Release Flow : Our Branching strategy
The Mobile team uses a trunk-based branching strategy to help us develop DEM V2 quickly and deploy it regularly. This strategy needs to be able to scale to our development needs: a single repository that contains the entire Digital Edge for Mobile product
How We Deliver Changes to Production
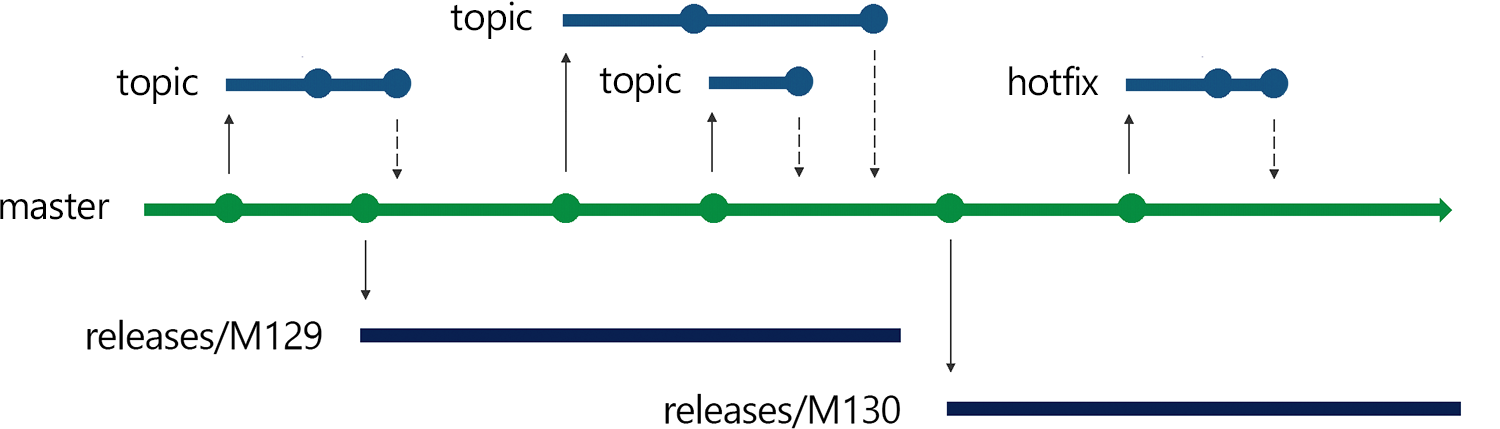
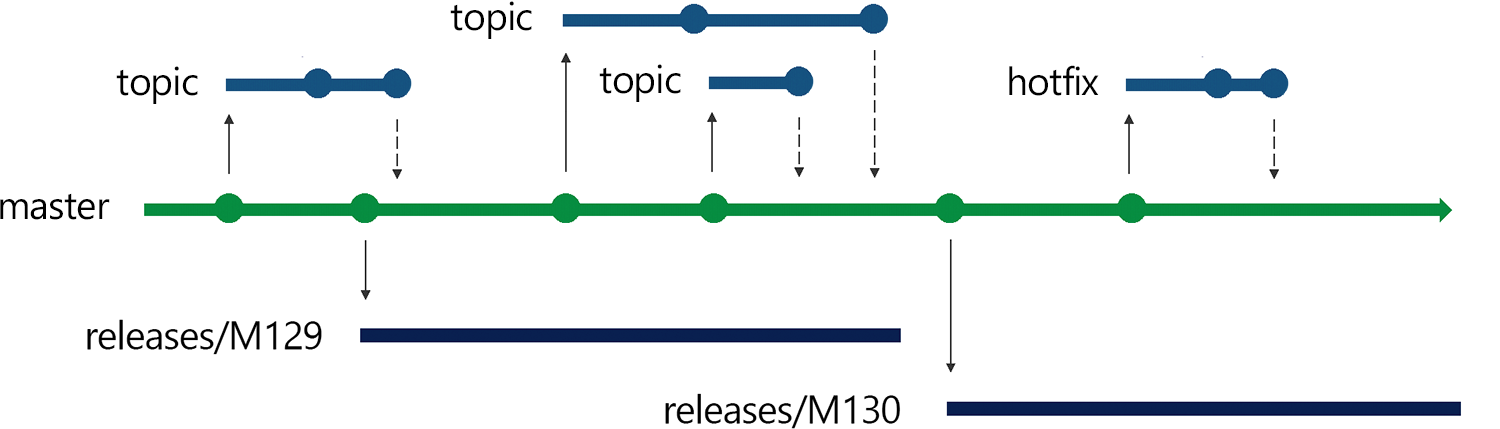
But unlike some trunk-based models, like GitHub Flow, we do not continuously deploy main(master) to production. Instead, we release our main branch every milestone by creating a branch for each release. When we need to bring hotfixes into production, we cherry-pick those changes from main into the release branch. It’s a strategy that we call “Release Flow“.
So instead of deploying every pull request to production, we deploy main to production at the end of each sprint milestone. This means that a new feature could take that long to get into production.
Development
Branch first step when a developer wants to fix a bug or implement a feature is to create a new branch off of our main integration branch, main(master). We create these short-lived "topic" branches any and every time we want to write some code. Developers are encouraged to commit early and to avoid long-running feature branches by using feature flags. With feature flags if the feature needs a little more bake time before it's ready to show off, if the product builds and deploys, it's safe to go to main. Once in main, the code ends up in an official build, where it's (again) tested, confirmed to meet policy, and digitally signed.
Push When the developer is ready to get their changes integrated and ship their changes to the rest of the team, they push their local branch to a branch on the server, and open a pull request. Since we have many developers working in our repository, each with many branches, we use a naming convention for branches on the server to help alleviate confusion and what we call "branch proliferation". Generally developers create a local branch named 'users/
/feature', where ' ' is (of course) replaced with their account name. For example, I create branches inside the users/milanskoric folder. Pull Request We can use Azure DevOps Pull Requests to control how developers topic branches are merged into main. Pull Requests ensure that our branch policies are satisfied: first, we build the proposed changes and run a quick test pass. Next, we require that other members of the Digital Edge team review the code and approve the changes. Code review picks up where the automated tests left off, and are particularly good at spotting architectural problems. Manual code reviews ensure that more engineers on the team have visibility into the changes and that code quality remains high.
Merge Once all the build policies are satisfied and reviewers have signed off, then the pull request is completed. This means that the topic branch is merged into the main integration branch, 'main'.
This is how developers get changes into our codebase -- and at this point, our branching strategy looks like a typical trunk-based development model. Commits will be merged to main branches on a regular basis (typically every Monday).
We can use a couple of Azure DevOps features to help enforce this structure and keep the main branch clean. Branch policies prevent direct pushes to main. We require a successful build (including passing tests), signoff by the owners of any code that was touched, and a handful of external checks verifying corporate policies before a PR can be completed.
Night build
The main branch corresponds to a version that is not yet tagged (as pre-release or stable). This is also the "nightly" branch where we build our code every business day at midnight.
To be sure our code always compiles, it is recommended to build it regularly in a reference environment. This approach provides a new way to try the latest-and-greatest in our code through our new nightly build feed. Nightly builds will enable a tighter feedback loop with those of you in our delivery and test team as we strive for quality and performance improvements. It also allows you to test and review changes and features that will appear in the next pre-release. This is where anything that doesn't fit into the stable or prerelease should be targeted.
At this moment some core functionality is code-complete and not fully tested. Major bugs are still present and some features may still not be available.
Pre-Release Sprint
At the end of a sprint, we create a label in the main branch. For example, at the end of sprint 128, we create new label releases/S128 and (debug) deployment of that code because we want to get early feedback.
Most of the functionality is complete. Know issues are present. The pre-release version has had some testing and bug fixing.
Stable Releases at Sprint Milestones
At the end of a milestone we create a deployment branch (and put labels too) from the main branch: for example, at the end of sprint milestone 129, we create a new branch releases/M129. We then put the milestone 129 branch into production.
Once we've branched to our deployment branch, the main branch remains open for developers to merge changes. These changes, of course, do not get deployed to production - they'll be deployed during the next milestone deployment.

We use the release branch to stabilize the release candidate and continue development for our next version in main.
Release candidate: all functionality is complete and tested. The packages are ready to be published.
Releasing Hotfixes
Obviously, some changes need to go to production more quickly. We generally won't add big new features in the middle of a sprint, but sometimes we want to bring a bug fix into DEM V2 quickly to unblock users. Sometimes we have embarrassing typos that we want to correct. And sometimes we have a bug that causes an availability issue, which we call a "live site incident".

When this happens, we start with our normal workflow: we create a branch from main, get it code reviewed, and complete the pull request to merge it. We always start by making the change in main first: this allows us to create the fix quickly, and validate it locally without having to switch to the release branch locally.
More importantly, by following this process, we're guaranteed that our change goes into main. This is critical for us: if we were to fix a bug in the release branch first, and accidentally forget to bring the change back to main, we would have a recurrence of the bug during the next deploy - when we create our sprint 130 release branch from main in next milestone. It's particularly easy to forget to do this during the confusion and stress that can arise during an outage. So by always bringing our changes to main first, we
If we were to hotfix production directly, we might accidentally forget to bring a change back to main for the next release. But by bringing changes into main first, we ensure that we never have regressions in production.
Note
The only exception, of course, is when the change doesn’t make sense to bring into main. Perhaps there’s been some refactoring that means that this bug doesn’t exist in main anymore. That’s the only time pull requests can go directly into a release branch without going through the main first.
Moving On
After the next milestone, we'll finish adding features to sprint 130, and we'll be ready to deploy those changes. To deploy, we'll create the new release branch, releases/M130 from main, and deploy that.
For example, once we finish development in sprint 130, we’re ready to deploy those changes to production; at that point, we forget about the old releases/M129 branch. Instead, we create a new branch named releases/M130 from main and deploy it.
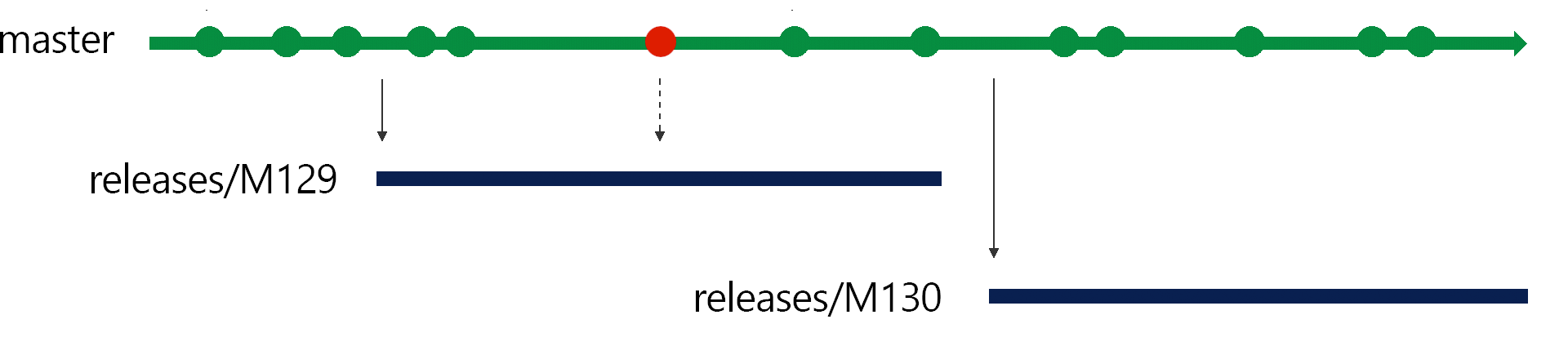
Once the releases/M130 deployment finishes we don’t care about the old releases/M129 branch anymore since we were very careful to ensure that any changes that we brought into the sprint 129 branch as a hotfix was also made in main. So those changes will also be in the releases/M130 branch that we create. That branch 129 is only of historical interest. We could even delete it but we keep two latest releses branch a live for support. live for support.
At this point, we'll actually have two branches in production. This raises an interesting problem, if we need to hotfix a change in this moment, we may need to hotfix two different releases: the sprint 129 release and the sprint 130 release. In these cases, we'll port the hotfix to both release branches and deploy both release branches.
With this simple branching strategy and adopting a consistent naming convention, we'll be able to support:
- Applications that have one or more supported releases
- Continuous development of new features
- Continuous delivery of value to your users
Created new ways to stay healthy
Before, we would let code bugs build up until the end of a code phase (the "code complete). We would then discover them, work on fixing them, rinse and repeat. This created a "roller coaster" of bugs, and as the number of bugs dropped, so did team morale as they did nothing but work on bug fixes instead of implementing new and fun features.
Now, we implement what we call a "bug cap". A bug cap is calculated by the following formula:
# of engineers x 5 = bug cap
If a team's bug count exceeds the bug cap at the end of a sprint, they stop working on new features until they are back down under their cap. A version of paying down their debt as they go.
The characteristics of our team:
- Cross discipline
- Self-managing
- Clear charter and goals for 12 months
- Physical team rooms
- Own features in production
- Own deployment of features
Shielding distractions
Teams have come up with their own way to provide focus and assist with an interrupt culture in the form of bugs and live-site incidents.
Teams will self-organize itself each sprint into two distinct teams: Features (F team) and Shielding (L teams). The F-team works on committed features and the L-team deals with all live site issues and interruptions. The rotating cadence is established by the team and it allows for members to plan activities outside of work much easier.
Checklist and lessons from the field
Checklist
- Keep it simple and expand branching complexity as needed
- Organize your code into shippable units
- Use a consistent naming strategy for your branches
- Build with every check-in
- Create a CI/CD pipeline using gated check-ins and automated testing
Lessons from the field - things to avoid
- Avoid going branch crazy!
- merging changes comes with complexity and a cost
- there's no need to have a separate branch per environment
- Avoid using cherry-picking to get your code to production
- Do not attempt to solve people or process problems with tools
Q&A
Why should branches be short-lived? By keeping branches short-lived, merge conflicts are kept to as few as possible.
Why remove branches? Your goal should be to get changes back into main as soon as possible, to mitigate long-term merge consequences. Temporary, unused, and abundant branches cause confusion and overhead for the team.
More info
- Trunk-based branching strategy
- Feature flags
- Azure DevOps Pull Requests
- Azure DevOps Build validation
- Azure DevOps Automatically include code reviewers
- Azure DevOps require approval from external services
- Git patterns and anti-patterns for successful developers
- Feature Flags: Release Small and Often, Simplify Workflow
- The best branching model to work with Git
- Improving Azure DevOps cherry-picking